Transition matrix model สำหรับกลุ่ม Low default portfolios #1
Low default, Moody’s external rating, Smoothing techniques
Blog ตอนนี้เป็นเรื่องเกี่ยวกับการทำ Transition matrix สำหรับ Portfolio ที่มีข้อมูลค่อนข้างจำกัด ลักษณะ Portfolio ที่ Credit risk modeler ไม่มีใครอยากเจอ คือกลุ่ม Portfolio ที่มีข้อมูลน้อยในเรื่องของจำนวน หรือข้อมูลค่อนข้างจำกัดในเรื่องของช่วงเวลา ซึ่ง Blog ตอนนี้ขอยกตัวอย่างลักษณะที่เป็น Low default หรือกลุ่มประชากรที่มีข้อมูลน้อย และมีหนี้เสียน้อยด้วยเช่นกัน
เนื่องจาก Blog ตอนนี้จะไม่ได้ลงรายละเอียดเกี่ยวกับ Transition matrix แล้ว เพราะเคยเขียนไว้ทั้งหมดแล้วอย่างละเอียด สามารถติดตามได้จาก Link ที่ให้ไว้ด้านล่าง หากอยากเข้าใจมากขึ้น
Low default portfolio
Low default portfolio อย่างที่บอกไว้ว่าคือกลุ่มสินเชื่อที่มีลักษณะเฉพาะ คือมีจำนวนหนี้เสียน้อย หรือรวมไปถึงมีขนาดของประชากรที่น้อยด้วยเช่นกัน ซึ่งส่วนมากมักเจอในกลุ่มลูกหนี้ที่เป็นสถาบันการเงิน หรือ Financial institution ที่แน่นอนว่าโอกาสเกิดหนี้เสียแทบจะไม่มี
ดังนั้นข้อมูลสินเชื่อลักษณะนี้ ย่อมเกิดปัญหาในเชิง Credit risk อยู่ 2 กรณีหลัก ๆ คือ
- ไม่มีข้อมูลมาใช้ในการพัฒนาแบบจำลอง
- ข้อมูลมีลักษณะที่ค่อนข้าง Fluctuated จนไม่สามารถนำมาใช้ได้ ที่เกิดกรณีเช่นนี้ เนื่องจากจำนวนประชากรที่ค่อนข้างน้อย หากเกิด Default ขึ้นเพียง 1 ราย อาจทำให้ค่า PD สูงกว่าความเป็นจริง เช่นข้อมูลทั้งหมดมีลูกหนี้ 3 ราย หากเกิด Default 1 ราย PD ที่เกิดขึ้นคือ 33.33% ซึ่งเป็นค่าที่สูงกว่า Unsecured portfolio ซึ่งผิดจาก Nature of business อย่างสิ้นเชิง
External rating

หลายครั้งจึงแก้ปัญหานี้ด้วยการใช้ข้อมูลจาก External sources เพื่อมาเป็น Reference ของค่า PD แทนที่จะใช้ข้อมูลจาก Internal data จริง ๆ เพราะข้อมูลของ External sources ไม่ว่าจะเป็น Moody’s หรือ S&P ล้วนแล้วแต่ได้รับความเชื่อถือ ที่สำคัญมีการเก็บข้อมูลจากกลุ่มตัวอย่างที่มากกว่า และยาวนานกว่า Internal data ของหลายที่แน่นอน ซึ่ง Blog ตอนนี้ใช้เป็น External rating ของ Moody’s
Dataset
Import ข้อมูล Moody’s default rate ที่เป็น Transition matrix สำหรับใช้ในการพัฒนาแบบจำลองนี้ โดยที่ Moody’s rating แบ่งออกเป็นทั้งหมด 22 เกรด (รวม Default) ซึ่งสามารถดูตัวอย่างได้จากรูปด้านล่าง

โดย Column ที่สนใจนำมาใช้เป็น Reference แน่นอนว่าต้องเป็น Default column ขอ Plot แสดงข้อมูลเพื่อความชัดเจนมากขึ้น โดยไม่แสดง Default row เพราะมีค่าเป็น 100% อยู่แล้ว
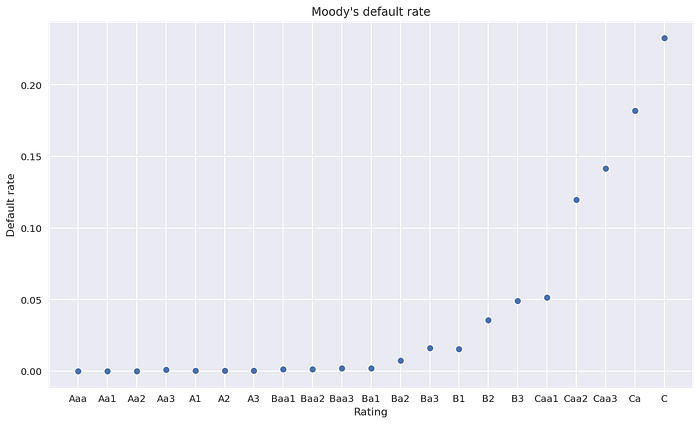
จาก Plot แสดงให้เห็นว่าข้อมูล External source ก็ยังมีปัญหาอยู่ คือค่า PD ยังไม่เรียงกันตามความเสี่ยง เพราะเมื่อ Rating แย่ลงค่า PD ควรมีค่าที่สูงขึ้นตามไปด้วย แต่จาก Plot เห็นได้ว่า Rating Aa3 ที่ดีกว่า A1 แต่มีค่า PD ที่สูงกว่า (0.0009 > 0.0004) หรือ Rating Ba3 ที่ดีกว่า B1 แต่มีค่า PD ที่สูงกว่า (0.0163 > 0.0155) เป็นต้น
ดังนั้นก่อนนำข้อมูล Default rate ไปใช้งานต่อ ต้องมีการซ่อมหรือทำ Adjustment บางอย่างเพื่อให้ข้อมูลเป็นไปตาม Expectation ก่อน แต่ก่อนไปที่ขั้นตอน Adjustment ขอเก็บ Original matrix ไว้ก่อน เพื่อการ Plot เปรียบเทียบในตอนท้าย
Smoothing adjustment
เนื่องจากปัญหา Un-ranking ของ Default rate ทำให้ต้องเกิดขั้นตอนการทำ Adjustment เพิ่มเติม หมายความว่าหากข้อมูล External มีลักษณะที่ Rank ตามที่ต้องการแล้ว อาจข้ามขั้นตอนนี้ไปได้เลย
เทคนิคการทำ Smoothing อาจทำได้หลากหลายวิธี เช่นการทำ Exponential smoothing หรือใช้ Model เข้ามาช่วยในการทำงาน ซึ่ง Blog ตอนนี้เลือกใช้เป็น Model เข้ามาช่วยในการทำงาน โดยที่เลือกเป็น Linear regression ปกติ แต่ Fitting ด้วย Logarithmic formation เพื่อให้ข้อมูลที่ Fitted ออกมามีความโค้ง ตามรูปที่ควรจะเป็น
เนื่องจากข้อมูล 3 Ratings แรกมีค่าเป็น 0 จึงไม่มีผลต่อ Regression model ดังนั้นให้ตัดออกไปจากการคำนวณ จากนั้นแยก Targer หรือคือ Default rate และ Feature ในที่นี้คือ Index ของข้อมูล โดยให้ Assume ว่าเมื่อเลข Index มีค่าเท่านี้ Default rate ควรมีค่าเป็นเท่าใด เป็นต้น
Fitting linear regression โดยให้ Target หรือ y เป็น Logarithmic formation ด้วยการใส่ np.log() เข้าไป จากนั้นวัดผลลัพธ์ด้วย R-Square
R-Square: 0.9539ใช้ model.predict() และ Inverse logarithmic formation ด้วย np.exp() เพื่อค่ากลับมาเป็น Default rate และ pd.concat() กลับไปที่ Table เดิมเพื่อเปรียบเทียบค่าจริงและค่าจาก Linear regression model
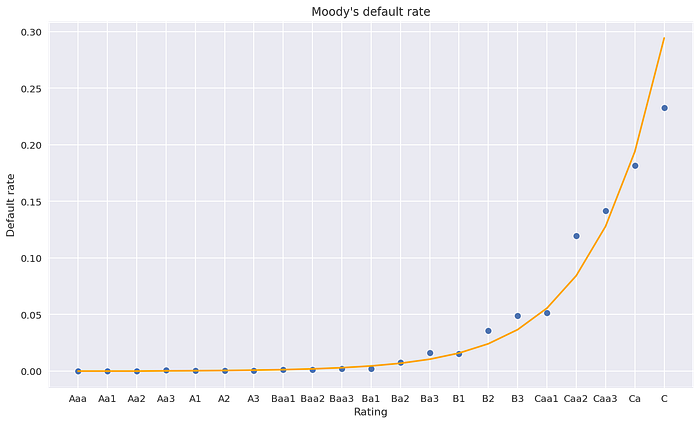
เส้นสีส้มคือ Prediction จาก Linear regression model ซึ่งเห็นได้ว่าค่าที่มีปัญหาเรื่อง Un-ranking ได้ถูกแก้ไขด้วย Model เรียบร้อยแล้ว ซึ่งผลลัพธ์จาก Model นี้จะถูกนำไปใช้ต่อ
แต่ก่อนไปถึงขั้นตอนต่อไป อย่างที่บอกไว้ตอนแรกว่าการ Smoothing สามารถทำได้หลายวิธี ซึ่งอาจทำได้ด้วยเทคนิค Exponential smoothing ใน Python สามารถใช้วิธีการเขียนเป็นฟังก์ชั่น Exponential ขึ้นมา และใช้ curve_fit() ฟังก์ชั่นจาก Scipy แก้ปัญหาเหล่านี้
'''
# Example for curve fitting approach
from scipy.optimize import curve_fit# Define exponential function
def fittingPD(x, a, b, c):
return a * (b**x) + c# Initial guesses
initialGuesses = [1, 1, 1]# Fitting
popt, pcov = curve_fit(fittingPD, x, y, initialGuesses)# Result
fittingPD(x, *popt)
'''
Code ด้านบนเป็นตัวอย่างการใช้ Exponential เพื่อมาเป็นฟังก์ชั่นในการ Smoothing ซึ่งอาจนำไปปรับใช้ต่อไปได้
Next step
เขียนมาถึงตรงนี้… สิ่งที่ได้มาคือ Fitted default rate จาก External rating ที่ Ranking เป็นไปตาม Expectation ของ Rating’s definition แล้ว ในตอนต่อไปเป็นส่วนของ Model ที่เหลือคือ การนำ Fitted default rate นี้ ไปใช้กับข้อมูล Internal ที่เป็น Low default portfolio
