การทดสอบ Multicollinearity ใน Linear regression model ด้วย Python
Scatter matrix, Correlation matrix and Variance Inflation Factor (VIF)
มาถึงการทดสอบอีกสมมติฐานของ Linear regression model ที่บอกไว้ว่า No or little multicollinearity ดังนั้นก่อนนำโมเดลไปใช้งาน ควรต้องทดสอบ Multicollinearity ของ Independence variables ก่อน เพื่อให้แน่ใจว่าโมเดลสามารถสรุปเป็น BLUE (Best Linear Unbiased Estimator) ได้
เนื้อหาในตอนนี้ยังใช้เป็นข้อมูล Macroeconomics variables ที่เป็นส่วนนึงของ Forward-looking PD ใน IFRS 9 แต่เช่นเดิมที่ว่า สามารถนำไปประยุกต์ใช้กับ Linear regression model อื่นได้เช่นกัน

Multicollinearity
ก่อนอื่นต้องยกตัวอย่างให้เห็นภาพง่าย ๆ ของสมการ Linear regression เช่นต้องการหาความสัมพันธ์ของปริมาณการกินอาหาร และน้ำหนักตัวที่เพิ่มขึ้น (Response variable, Target) ความสัมพันธ์ที่เกิดขึ้นอาจไม่ได้ซับซ้อน เช่น เมื่อปริมาณการกินมาก น้ำหนักตัวก็เพิ่มขึ้นมากเช่นกัน ความสัมพันธ์ที่สามารถอธิบายได้ด้วยตัวแปรเดียว เรียกว่า Simple linear regression
แต่ถ้าเพิ่มเงื่อนไขขึ้นมา เช่น ต้องการศึกษาน้ำหนักตัวในกลุ่มนักกีฬา ความสัมพันธ์ก่อนหน้านี้อาจไม่จริงเสมอไป เพราะนักกีฬาเป็นกลุ่มที่มีกิจกรรมที่ Active มากกว่าคนทั่วไป ดังนั้นตัวแปรที่มีผลกับน้ำหนักตัวที่เพิ่มขึ้น อาจมีมากกว่าปริมาณการกินอาหาร เช่น ชนิดของอาหาร จำนวนแคลอรี่ เป็นต้น เมื่อการอธิบายต้องมีมากกว่า 1 ตัวแปร สมการที่เกิดขึ้นจึงเรียกว่า Multiple linear regression
ปัญหา Multicollinearity เกิดขึ้นใน Multiple linear regression คือการที่สมการต้องการ Explanatory variables มากกว่า 1 ตัวแปร แต่ตัวแปรนั้นสามารถอธิบาย Response variable ได้แบบเดียวกัน หรือในความเป็นจริงแล้ว Explanatory variables มีความสัมพันธ์กันเอง เมื่อเป็นเช่นนี้ทำให้ Model ที่ออกมาไม่มีความน่าเชื่อถือ
Explanatory variables
Blog ตอนนี้อาจไม่ได้เริ่มต้นด้วย Model เหมือนตอนก่อนหน้านี้ เพราะต้องการเพิ่มตัวแปร X (Explanatory variables) เพื่อให้เห็นเกิดขึ้นของ Multicollinearity เพราะจากประสบการณ์ที่ผ่านมาปัญหา Multicollinearity มักเกิดขึ้นเมื่อเพิ่มตัวแปร X เกิน 4 ตัวแปร ดังนั้น Blog ตอนนี้จึงใช้เป็น X ทั้งหมด 5 ตัวแปร
Graphical method
การทดสอบ Multicollinearity ด้วย Graphical method อาจไม่เป็นนิยมมากนัก เนื่องจาก Statistical method ทำได้ง่ายกว่า แต่ Blog ตอนนี้อาจกล่าวถึงเนื้อหาไว้เผื่อเป็นทางเลือก
Scatter matrix
Scatter matrix เป็นการ Plot scatter ของ Independence variables ทุก ๆ ตัว ดังนั้น Blog ตอนนี้มี Independence variables ทั้งหมด 5 ตัว ผลลัพธ์จึงออกมาเป็น Matrix ขนาด 5x5
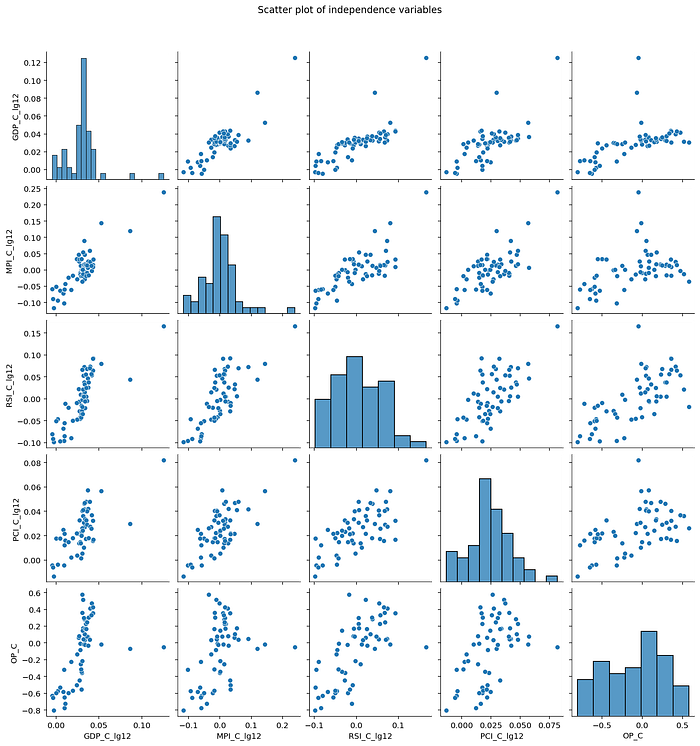
Plot ที่สนใจคือคู่ตัวแปรที่ให้ผลไปในทาง “เส้นตรง” เช่นตัวแปร ‘GDP_C_lg12’ ที่ความสัมพันธ์ “ค่อน” ไปทางเส้นตรงกับทุก ๆ ตัวแปร เช่นเดิมของการ Graphical method คือการที่สรุปผลยากจากการมองด้วยตา ตัวแปร ‘GDP_C_lg12’ จึงต้องสงสัยว่าอาจเกิด Multicollinearity ขึ้น
Statistical method
แน่นอนว่าการใช้ Statistical method ย่อมสามารถสรุปผลได้ดีกว่า เพราะมีตัวเลขทางสถิติเป็นเครื่องมือใช้ยืนยัน Blog ตอนนี้ขอนำเสนอ 2 เครื่องมือคือ Correlation matrix และ Variance Inflation Factor (VIF)
Correlation matrix
Correlation matrix คือการหา Correlation ของ Independence variables ทุกตัวแปรเช่นกัน ผลลัพธ์ที่ออกมาอยู่ในช่วง -1 ถึง 1 ซึ่งเครื่องหมายคือทิศทางของความสัมพันธ์ว่าเป็น Negative หรือ Positive relationship
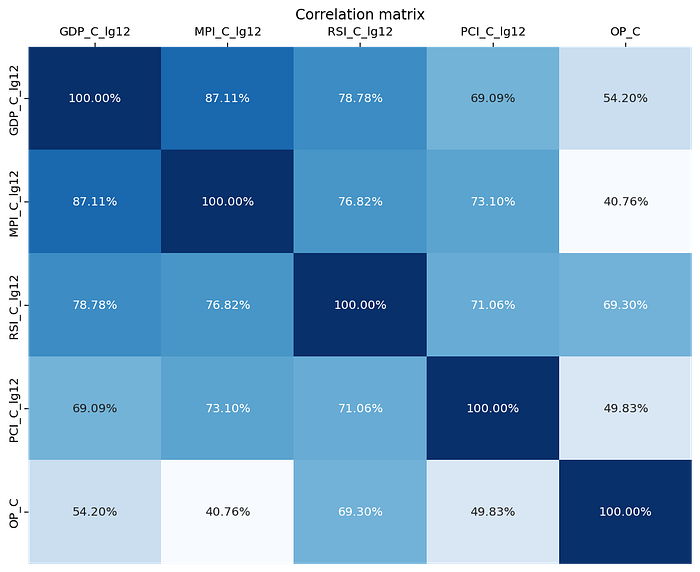
หากมองที่ตัวแปร ‘GDP_C_lg12’ เช่นเดิมอาจเห็นได้ว่า Correlation ที่เกิดขึ้นกับตัวแปรอื่น มีค่าที่ค่อนข้างมาก ถึงตอนนี้อาจสรุปจาก Scatter plot และ Correlation ได้แล้วว่า ‘GDP_C_lg12’ เกิด Multicollinearity ขึ้น แต่ตัวแปรอื่น ๆ ที่ให้ค่าสูงเช่นกันแต่ Scatter plot ไม่ชัดเจน จะสรุปผลได้อย่างไร?
Variance Inflation Factor (VIF)
เพื่อให้เกิดการสรุปผลที่แน่นอนมากกว่า Correlation matrix จึงควรมี Statistic 1 ค่า เพื่อเทียบกับ Threshold ว่าเกิด Multicollinearity ขึ้นหรือไม่ วิธีการที่นิยมใช้เป็นสากลคือ Variance Inflation Factor (VIF)
VIF เป็นการรัน Regression ระหว่าง Independence variables ด้วยกันเอง โดยให้ 1 ตัวแปรเป็น Dependence variable ในขณะตัวแปรที่เหลือเป็น Independence variables สลับกันไปเรื่อย ๆ จนทุกตัวแปรเป็น Dependence variable ในแต่ละรอบการรันสามารถหาค่า VIF ได้จาก R² จากสูตรตามด้านล่าง
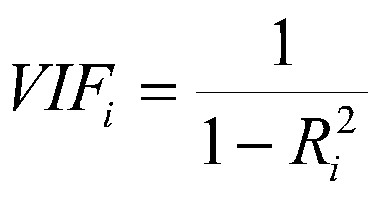
Threshold ที่นิยมใช้สำหรับ VIF อาจมีตั้งแต่ 2 ไปจนถึง 10 โดย Threshold ที่มากขึ้นหมายถึงการ Relax model มากขึ้นด้วยเช่นกัน Blog ตอนนี้ขอใช้ Threshold กลาง ๆ ที่ 5 เพื่อ Detect multicollinearity ใน Independence variables
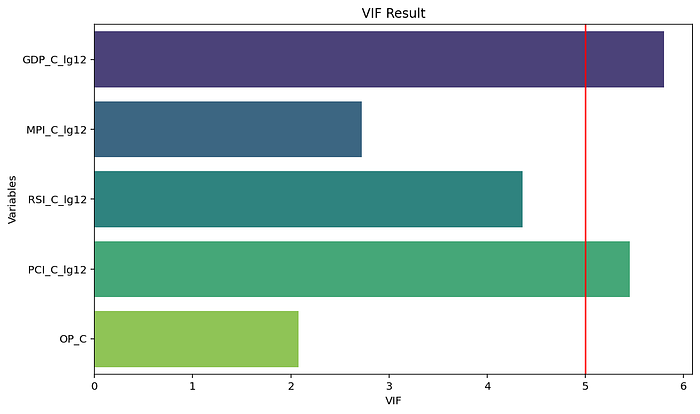
จากกราฟเห็นได้ว่าตัวแปร ‘GDP_C_lg12’ เกิด Multicollinearity ด้วยค่า VIF ที่เยอะที่สุดตามที่คาดการณ์ไว้ แต่ตัวแปร ‘PCI_C_lg12’ ก็มี Multicollinearity ด้วยเช่นกัน ในกรณีที่เกิดเหตุการณ์เช่นนี้ ต้องมีลำดับขั้นตอนในการจัดการ
Deal with multicollinearity
ขั้นตอนการจัดการกับปัญหา Multicollinearity อาจแบ่งออกเป็น 2 ทางง่าย ๆ ตามผลลัพธ์ที่เกิดขึ้น
- Drop ตัวแปรที่ VIF สูงที่สุดแล้ว รัน VIF เพื่อทดสอบ Multicollinearity อีกรอบ ถ้ายังมีตัวแปรที่ VIF สูงกว่า Threshold ก็ให้ Repeat ซ้ำไปเรื่อย ๆ จนกว่าทุกตัวแปรจะมีค่า VIF อยู่ภายใต้ Threshold จากตัวอย่างอาจต้อง Drop
‘GDP_C_lg12’แล้วรัน VIF เพื่อดูผลลัพธ์ใหม่อีกรอบ เพื่อดูว่าหลังจากที่ Drop‘GDP_C_lg12’ไปแล้ว‘PCI_C_lg12’ยังเกิด Multicollinearity อยู่หรือไม่ - Drop ตัวแปรด้วยผลลัพธ์จาก Model ตัวอย่างเช่นถ้าต้องการสร้างเป็น Linear regression model จากตัวแปรเหล่านี้ อาจทำการ Fitting model ด้วยตัวแปรทั้งหมดก่อน แล้วทำการทดสอบ VIF เป็นลำดับถัดไป ในหลายครั้งปัญหา Multicollinearity อาจถูกกำจัดไปตั้งแต่ต้นทางแล้ว
Blog ตอนนี้ขอให้ตัวอย่างจากวิธีที่ 2

จาก Model summary พบว่า ‘PCI_C_lg12’ มี p-value ที่สูงเกิน Significant threshold (0.05) ดังนั้นจึงต้อง Drop ‘PCI_C_lg12’ พร้อมกับรัน Regression model ใหม่อีกรอบ
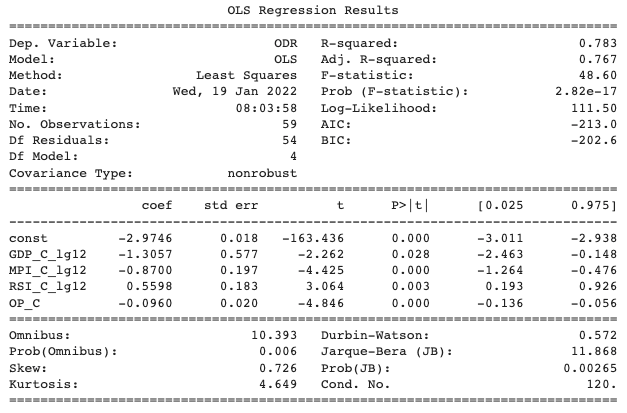
เมื่อ Drop ตัวแปร ‘PCI_C_lg12’ออกไปและรัน Regression ใหม่ ผลลัพธ์ที่ได้คือทุกตัวแปรผ่าน Significant threshold ที่ 0.05 ทั้งหมดแล้ว แต่ทั้งหมดนี้ยังไม่ได้การันตีว่าปัญหา Multicollinearity จะไม่เกิดขึ้น ดังนั้นจึงจำเป็นต้องทดสอบ VIF อีกรอบ

จากกราฟเห็นได้ว่าตัวแปรทั้ง 4 ตัวแปรไม่มีปัญหา Multicollinearity เหลืออยู่แล้ว ดังนั้น Model ที่เกิดขึ้นจึงสามารถนำไปทดสอบสมมติฐานของ Linear regression assumptions ต่อไป หากสมมติฐานที่เหลือทดสอบผ่าน ก็สามารถสรุปได้ว่า Model นี้เป็น Best Linear Unbiased Estimator (BLUE)
Conclusion
ตอนนี้คือตอนเกือบสุดท้ายสำหรับการทดสอบสมมติฐานของ Linear regression model แล้ว สำหรับ IFRS 9 แล้ว ทุก Forward-looking model ที่พัฒนาด้วย Linear regression จำเป็นต้องผ่านการทดสอบสมมติฐาน “ทุกข้อ” ก่อนการนำไปใช้งาน เพื่อหลีกเลี่ยงปัญหาที่อาจเกิดขึ้นกับ Validator, Auditor หรือ Regulator
สำหรับ Colab notebook ของเนื้อหาตอนนี้ สามารถดูได้ที่ Link ด้านบน
