การทดสอบ Normality ใน Linear regression model ด้วย Python
Histogram, Box plot, QQ Plot, Shapiro-Wilk and Anderson-Darling
1 ใน Model assumption ของ Linear regression model คือ Residual (Error) ต้อง Follow normal distribution สำหรับ Linear regression model เป็นสิ่งที่ใช้บ่อยมากสำหรับงาน Credit risk อาจรวมไปถึงสายงานอื่น ๆ ด้วยเช่นกัน เพราะเป็น Model ที่พื้นฐานที่สุด ที่ให้ผลลัพธ์ที่ค่อนไปทางดีกับข้อมูลประเภทต่าง ๆ

สำหรับ IFRS 9 ในส่วนที่เป็น Forward-looking model หลาย ๆ ที่ได้ Leverage linear regression model เพื่อการ Forecast PD ในอนาคตด้วยความสัมพันธ์ที่เกิดขึ้นกับ Macroeconomics variables เช่นกัน ดังนั้นก่อนการนำโมเดลไปใช้งาน จึงมีการตรวจสอบ Model assumption ต่าง ๆ ให้ครบถ้วนเสียก่อน
Model
ก่อนอื่นขอสร้าง Multiple linear regression ด้วยข้อมูล Logit ODR และตัวแปร Macroeconomics variables โดยเลือกมาทั้งหมด 2 ตัวแปร เพื่อให้ได้เป็น Estimated model เพื่อคำนวณ Error หรือ Residual ต่อไปตามลำดับ

การทดสอบ Residual normality สามารถทำได้หลายวิธี ซึ่งสามารถแบ่งออกเป็น 2 วิธีการใหญ่ ๆ ได้คือ
- Graphical method เป็นการใช้ Visualization เพื่อเป็นการตัดสินว่าค่าของ Residual เป็น Normal distribution หรือไม่ ซึ่งเป็นวิธีการที่ง่าย แต่ค่อนข้าง Bias ด้วย Human judgement เพราะแน่นอนว่าสายตาของแต่ละคน ย่อมมีความแตกต่างกันในเรื่องของการมอง ดังนั้นวิธีการนี้จึงอาจเป็นการ Prelim ข้อมูล แต่ยังไม่นำไปสู่ Conclusion วิธี Graphical method ประกอบไปด้วย Histogram plot, Box plot และ Q-Q Plot เป็นต้น
- Statistical method เป็นการใช้ Statistical theory ต่าง ๆ เพื่อใช้ทดสอบกับ Hypophysis วิธีการนี้ให้ผลลัพธ์ที่ค่อนข้างเป็นสากล เพราะมี Theory รองรับ รวมไปถึงการช่วยลด Human bias และนำไปสู่ Conclusion ที่ดีได้ ตัวอย่างการทดสอบด้วย Statistical method เช่น Shapiro-Wilk และ Anderson-Darling เป็นต้น
Histogram plot
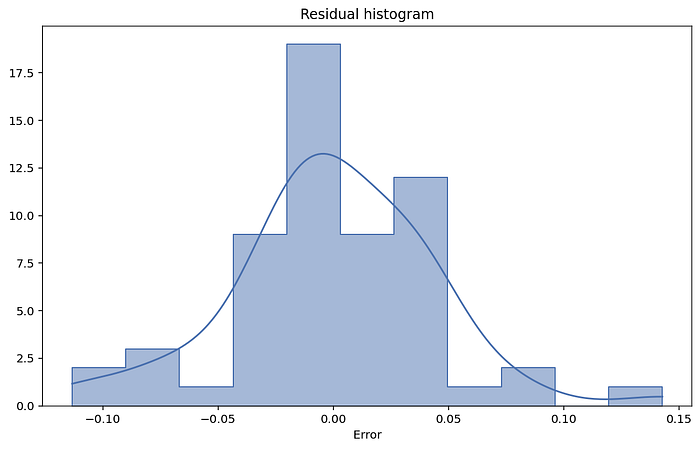
การดูค่าจาก Histogram เป็นวิธีการตรวจสอบ Normality ที่ตรงไปตรงมาที่สุด สามารถนำค่า Residual จาก Model สามารถ Call ได้จาก Function .resid จากนนั้นนำค่าที่ได้มา Plot histogram แล้วพิจารณาว่า Curve ที่ออกมาในรูปของระฆังคว่ำเป็นไปตาม Normal distribution แล้วหรือไม่
Box plot
ต่อมาเป็นวิธีการ Box plot จัดว่าเป็นวิธีการที่ง่ายเช่นเดียวกันกับ Histogram plot แต่ต่างกันที่การ Interpret ผลลัพธ์ โดยให้พิจารณาจากเส้นแบ่งในกล่อง Box plot หากค่ามี Mean และ Medium มีค่าใกล้กันหรือเส้นซ้อนทับกันมาก ๆ หมายความว่า Residual มีโอกาสที่จะเป็น Normal distribution มากเช่นกัน
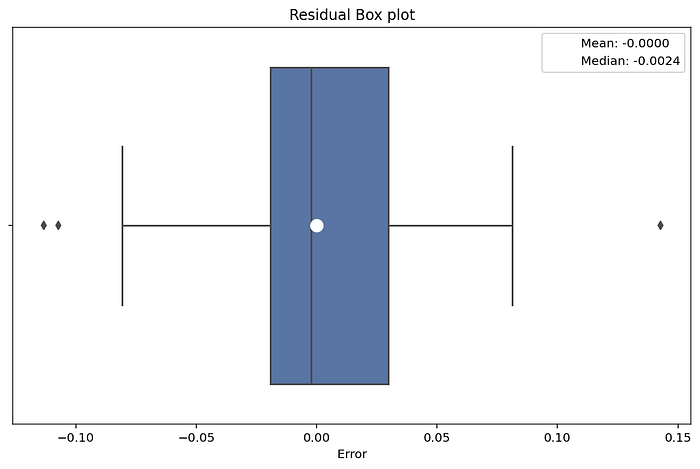
จาก Box plot ด้านบนเห็นได้ว่า Mean และ Medium มีค่าที่ใกล้เคียงกัน จึงอาจ Assume ได้ว่า Residual “อาจจะ” เป็น Normal distribution
Q-Q Plot
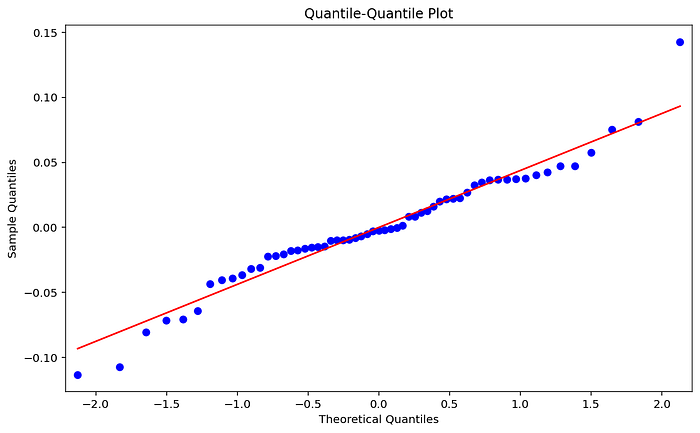
วิธีการสุดท้ายสำหรับ Graphical method ที่อยากนำเสนอคือ Q-Q Plot หรือ Quantile-Quantile Plot ซึ่งสามารถใช้ Library statsmodels qqplot() Function สำหรับการ Plot วิธีการอ่านผลคือ ถ้าจุดสีน้ำเงินมีลักษณะ Follow (เกาะ) เส้นสีแดงที่เอียง 45 องศาได้ดี อาจจะ Assume ได้ว่า Residual เป็น Normal distribution
Shapiro-Wilk
ทั้ง 3 วิธีการ Plot ที่ได้นำเสนอไป หากสังเกตดูจะพบว่า ผลลัพธ์จากการ Plot มีคำว่า “อาจจะ” อยู่ทั้งหมดเลย นี่คือตัวอย่างของคำว่า Human bias ที่นำไปสู่ Conclusion ที่ต่างกันไปในแต่ละคน ดังนั้นการใช้ Statistical method อาจเป็นสิ่งที่นำไปสู่ Conclusion เดียวกันได้
วิธีทาง Statistic ที่อยากนำเสนอวิธีแรกคือ Shapiro-Wilk เป็น Statistic ที่ใช้วัดว่าข้อมูลมีการกระจายตาม Normal distribution มากหรือน้อยอย่างไร Shapiro-Wilk เหมาะกับข้อมูลที่มีขนาดเล็ก (Small sample size) ตัวเลขกลม ๆ ที่หนังสือเขียนไว้คือ <1000 Observation ดังนั้นถ้านำมาใช้สำหรับ IFRS 9 Forward-looking model ย่อมสามารถทำได้
วิธีการ Interpret ผลลัพธ์สามารถใช้ค่า p-value เพื่อความสะดวก โดยอาจตั้งเป็น Threshold หรือ Alpha ที่ 5% ซึ่ง Hypothesis testing คือ
- H0: The data is followed normal distribution
- H1: The data is not followed normal distribution
เพราะฉะนั้นถ้า
- p-value ≤ alpha: Reject H0 → Not normal
- p-value > alpha: Failed to reject H0 → Normal
ดังนั้นคำตอบของ Linear regression ว่า Model residual เป็น Normal distribution หรือไม่คือ Residual distribution is normal ด้วย p-value = 0.1219 (> 0.05)
Shapiro-Wilk statistic: 0.9680
Shapiro-Wilk p-value: 0.1219
Residual distribution is normalAnderson-Darling
วิธีการทดสอบวิธีสุดท้ายที่อยากนำเสนอใน Blog ตอนนี้คือ Anderson-Darling เพราะผลลัพธ์ที่ออกจาก Python library อย่าง Scipy return เฉพาะค่า Critical values ที่ Significant level ต่าง ๆ เท่านั้น ไม่ได้มีค่า p-value เหมือนที่คุ้นเคย ดังนั้นการ Interpret ผลจึงไม่เหมือนกับ p-value โดยที่
- Test statistic < Critical value: Fail to reject H0 → Normal
- Test statistic ≥ Critical value: Reject H0 → Not normal
ผลลัพธ์ที่ออกมามีความแตกต่างกันไปในแต่ละ Significant level ที่ Critical value เปลี่ยนไปเช่นกัน ตามผลลัพธ์ที่อยู่ด้านล่าง
Anderson-Darling statistic: 0.6105
Residual distribution is not normal at significance level: 15.0 with critical values of: 0.543
Residual distribution is normal at significance level: 10.0 with critical values of: 0.619
Residual distribution is normal at significance level: 5.0 with critical values of: 0.742
Residual distribution is normal at significance level: 2.5 with critical values of: 0.866
Residual distribution is normal at significance level: 1.0 with critical values of: 1.03เนื่องจากการใช้ Test statistic อาจมีความสะดวกมากนักในเรื่องของการแปลผล จึงมี Paper ที่เสนอวิธีเปลี่ยนค่า Anderson-Darling test statistic ให้เป็นค่า p-value ซึ่งสามารถอ่านได้จาก
R.B. D’Augostino and M.A. Stephens, Eds., 1986, Goodness-of-Fit Techniques, Marcel Dekker.
เปลี่ยนวิธีการคำนวณค่า p-value ของ Anderson-Darling ที่ได้รับความนิยมมากที่สุด ซึ่งสูตรที่ใช้งานออกมาในรูปแบบ Condition เงื่อนไขตาม Test statistic ที่เกิดขึ้น โดยเริ่มจากเปลี่ยนค่า Anderson-Darling test statistic ให้เป็น AD* หรือ Adjusted value for small sample size
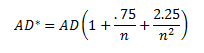
จากนั้น Apply AD* ตามเงื่อนไขที่เกิดขึ้นด้านล่าง
If AD* => 0.6, then p = exp(1.2937 - 5.709(AD*) + 0.0186(AD*)^2)
If 0.34 < AD* < .6, then p = exp(0.9177 - 4.279(AD*) - 1.38(AD*)^2)
If 0.2 < AD* < 0.34, then p = 1 - exp(-8.318 + 42.796(AD*)- 59.938(AD*)^2)
If AD* <= 0.2, then p = 1 - exp(-13.436 + 101.14(AD*)- 223.73(AD*)^2)เมื่อนำเงื่อนไขเหล่านี้มาเขียนเป็น Code จะได้ค่า p-value เพื่อนำไปใช้เทียบกับ Alpha threshold
Anderson-Darling adjustment: 0.6186Anderson-Darling p-value: 0.1074
Residual distribution is normalผลลัพธ์ของการคำนวณค่า p-value จาก Anderson-Darling test statistic ให้ผลลัพธ์คือ Model residual เป็น Normal distribution ด้วย p-value = 0.1074 (> 0.05)
Conclusion
จบแล้วสำหรับวิธีการทดสอบสมมติฐานของ Linear regression model ข้อที่ว่า Model residual ต้องเป็น Normal distribution ด้วยวิธีการที่หลากหลายนี้ ทำให้สามารถนำไปประยุกต์ใช้กับโมเดลได้หลาย ๆ กรณี ในตอนต่อ ๆ ไปคงเขียนถึงวิธีการทดสอง Model assumption อื่น ๆ ด้วยอีกเช่นกัน
สำหรับ Colab notebook ของเนื้อหาในตอนนี้ สามารถอ่านได้ที่ Link ด้านบน
