Part 1: Optical Character Recognition with TensorFlow and Keras
ไม่ได้ทำ Deep learning มานานแล้ว รู้สึกว่าไปเขียนเรื่องราวเกี่ยวกับ Stat ค่อนข้างเยอะ มันเกี่ยวข้องกับโปรเจคที่ทำอยู่ช่วงนี้ ทำให้ต้องยุ่งเกี่ยวกับ Stat อยู่พอสมควรเลย ยังมีอีกหลาย Networl model ที่ยังไม่ได้ลองทำ แต่ Blog ตอนนี้ได้แรงบันดาลใจจากซีรีส์เกาหลีเรื่อง Start-Up ที่กำลังดังมาก ๆ อยู่ใน Netflix ตอนนี้ (ฉายจบแล้ว)

ขอสปอยด์เนื้อหาในซีรีส์บ้างเล็กน้อย
“ในซีรีส์ฉากที่ทีมบริษัทของพระเอกต้องสร้างโมเดลให้ประทับคณะกรรมการ เพื่อชิงเงินลงทุนสำหรับ Project startup จำนวน 100 ล้านวอน ทีมของพระเอกเลือกที่ข้อมูลลายมือ นำมาสร้างโมเดลเพื่อหาว่าลายมือนั้นเป็นของจริงหรือของปลอม”
ไม่ต้องทำโมเดลให้เหมือนกันในซีรีส์ก็ได้ เพราะจากความรู้ตอนนี้คงอีกยาวไกลกว่าจะเดินทางถึงขั้นนั้น วันนี้ขอเริ่มต้นสั้น ๆ ก่อน โดยเริ่มจากการทำ Optical Character Recognition
Optical Character Recognition

Optical Character Recognition หรือที่เรียกกันอย่างย่อว่า OCR มันเป็นการอ่านตัวอักษรด้วยแสง ซึ่งสามารถอ่านข้อความที่เกิดจากการพิมพ์หรือเขียน ให้กลายเป็นข้อมูล Digital ซึ่งถูกเก็บอยู่ในรูปแบบตัวเลข
ณ ตอนนี้มี Application ในเชิงการทำงานในรูปแบบ OCR เยอะมาก มากไปกว่านี้แต่ละตัวมีความเก่งกาจจนการ Training model เองอาจไม่เรื่องจำเป็นอีกต่อไป แต่ไม่เป็นไร ถือว่าเป็นการเรียนรู้โมเดลในอีกรูปแบบ
Dataset
เริ่มต้นจากแนวคิดที่ง่ายที่สุดก่อน การที่จะรู้จำตัวอักษรได้ โมเดลจำเป็นต้องมีข้อมูลที่เป็นตัวอักษรก่อน หลายคนอาจคุ้นเคยดีเกี่ยวกับ MNIST Dataset ที่เก็บข้อมูลลายมือเขียนตัวเลข 0–9 จำนวน 70,000 รูป ซึ่งถูกนำมาใช้เป็นแบบฝึกหัดในเรียนรู้โมเดลกันอย่างแพร่หลาย ซึ่งสามารถอ่านข้อมูลเพิ่มเติมได้จาก Link ด้านล่าง
ต่อมาคือข้อมูลตัวหนังสือที่ต้องใช้ ครั้งนี้ขอเริ่มจากภาษาอังกฤษก่อน เพราะมีความง่ายกว่าภาษาไทยอยู่พอสมควร โชคดีที่ข้อมูลตัวหนังสือ A-Z มีคนทำไว้ให้เป็นไฟล์ CSV อย่างเป็นระเบียบอยู่ใน Kaggle ซึ่งสามารถโหลดได้จาก Link ด้านล่าง
Data processing
แม้ว่าข้อมูลที่ใช้ในวันนี้ถูกทำเอาไว้เป็นอย่างดีแล้ว (เทียบกับโมเดลก่อน ๆ) แต่ยังมีความจำเป็นต้องทำ Data processing สำหรับ Neural network
เนื่องจาก MNIST Dataset สามารถโหลดได้โดยตรงจาก tensorflow.keras.datasets อยู่แล้ว ดังนั้นข้อมูลที่ต้อง Download เหลือแค่ A-Z Dataset ยังมีความโชคดีอยู่ เนื่องจากข้อมูล A-Z ถูกเก็บไว้บน Kaggle ดังนั้นจึงสามารถใช้ Kaggle API โหลดมาไว้ที่ Google ได้โดยตรงเลย ส่วนวิธีการใช้งาน API เคยสอนไว้ที่ Link นี้แล้ว
Tensorflow version: 2.3.0
GPU is availableImport libraries ที่จำเป็นในการสร้าง OCR Model แต่ว่าตอนนี้คงยังไม่ได้แตะต้อง TensorFlow และ Keras มากนัก เพราะตั้งใจไว้ว่าจะจบถึงแค่ Data processing ที่ใช้งาน Numpy เป็นหลัก
Total rows: 372450, Total columns: 785อธิบายข้อมูล A-Z เพื่อให้เข้าใจมิติของข้อมูลมากขึ้น ข้อมูลมีทั้งหมด 372,450 Rows และ 785 Columns โดยข้อมูลแต่ละแถวรูปภาพตัวอักษร 1 ตัว ดังนั้น Column แรกจึงบ่งบอกตัวอักษร A ไปจนถึง Z ถูกเก็บด้วยเลข 0–25 (A = 0, …, Z = 25) ส่วน Columns ที่เหลือเป็นรูปภาพที่ถูกเก็บ Array number ขนาด 784 ดังนั้นรูปภาพจึงมีขนาดเท่ากับ 28 x 28 = 748 จาก Data structure แบบนี้ ทำให้สามารถออกแบบโปรแกรมเพื่อเก็บค่าให้เป็น Array สำหรับการ Training ได้
เก็บตัวแปรแยกกันระหว่างตัวหนังสือและรูปภาพ ประกาศ List ว่างไว้ 2 List ชื่อว่า az_labels และ az_images ตามลำดับ เริ่มต้น Loop function โดยให้เลือก Index ของ DataFrame ทีละ Index จากนั้นให้เก็บค่าตำแหน่งแรก [0] ไว้ที่ตัวแปร label และเก็บค่าตั้งแต่ตำแหน่งที่ 1 เป็นต้นไป [1:] แบบ Array ด้วยคำสั่ง .values ไว้ที่ตัวแปร image จากนั้น .append() ไว้ใน List ว่างทั้ง 2 ตามลำดับ สุดท้ายแปลง List เป็น Numpy array สำหรับ Neural network
Processing image done: 0
Processing image done: 50000
Processing image done: 100000
Processing image done: 150000
Processing image done: 200000
Processing image done: 250000
Processing image done: 300000
Processing image done: 350000
A-Z Labels shape: (372450,)
A-Z Images shape: (372450, 28, 28)มิติของ Labels array มีขนาด 1 มิติ มีจำนวนสมาชิก 372,450 ตัว และมิติของ Images array มีขนาด 3 มิติ โดยมีจำนวนสมาชิกขนาด 28 x 28 ทั้งหมด 372,450 ตัว

ทดลองแสดงรูปแรกของ Array ผลที่ได้ออกมาคือตัว A ซึ่งถูกแทนด้วยเลข 0 ซึ่งไปตามที่ออกแบบ Data structure เอาไว้ เนื่องจากข้อมูล A-Z เป็นภาพขาวดำ การแสดงผลด้วย plt.imshow() อาจได้สีไม่เหมือนแบบที่โชว์ เพราะโดน Default ของคำสั่งนี้จะพยายามเติมสีให้รูปเป็น RGB สีที่ออกมาจึงอาจผิดเพี้ยน หากต้องการให้การแสดงสีถูกต้องตามลักษณะข้อมูล (ป้องกันความสับสน) สามารถใช้ Option cmap = plt.cm.binary ได้ รูปที่แสดงออกมาจะได้มีที่เป็นขาวดำ
MNIST Train shape: (60000, 28, 28)
MNIST Test shape: (10000, 28, 28)ต่อมาเป็นการทำข้อมูล MNIST ซึ่งข้อมูลมีลักษณะเป็น Array อยู่แล้ว เนื่องจาก Dataset นี้ได้ถูกแบ่งทั้ง Images และ Labels เป็น Training set และ Testing set มาแล้ว ดังนั้นการใช้งานจึงต้องให้ตัวแปรมารับทั้งหมด 4 ตัว โดยขนาดรูปภาพจาก MNIST มีขนาด 28 x 28 เช่นกัน
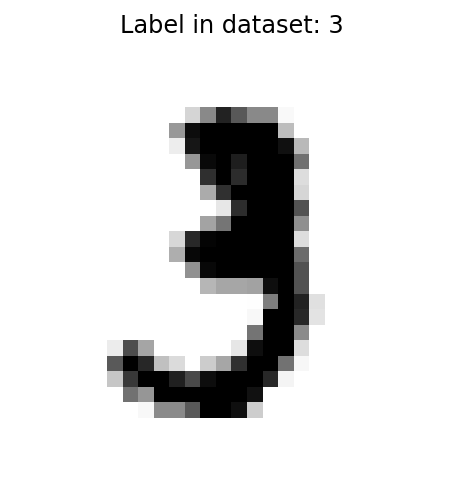
ขั้นต่อไปเป็นการรวม Dataset MNIST และ A-Z เข้าด้วยกัน **ข้อควรระวังของขั้นตอนนี้คือ Labels ของ A-Z ที่ถูกแทนด้วยเลข 0–25 ถ้า Stack array เข้าด้วยกันตรง ๆ จะทำให้ Labels A-J ไปซ้ำกับเลข 0–9 ดังนั้นให้ทำการเลื่อนตำแหน่งของ A-Z Labels ก่อนทำการ Stack array
การเลื่อนตำแหน่งทำได้ง่าย ๆ ด้วยการ + 10 ให้กับ A-Z Labels เพราะข้อมูล Labels MNIST มีค่า 0–9 ดังนั้น Label A จึงเริ่มต้นที่ 10 แทน จากนั้นให้ทำการ Stack ข้อมูลทั้ง 2 ชุดเข้าด้วยกัน โดยที่ Labels ให้ใช้ numpy.hstack() ส่วน Images ให้ใช้ numpy.vstack() เพราะไม่ต้องการให้มิติข้อมูลเปลี่ยน สุดท้ายให้ทำการเปลี่ยนค่าใน Images array ให้เป็น Float32 ที่เหมาะสมกับ Neural network ที่สุด
Labels shape: (442450,)
Images shape: (442450, 28, 28)
ทดลองสุ่มรูปขึ้นมา Plot เห็นได้ว่าเป็นรูปตัว A ดังนั้น Label ของตัว A ที่เปลี่ยนค่าไปแล้วจึงมีค่าเท่ากับ 10
ที่เขียนมาทั้งนี้เป็นการเตรียมข้อมูล สำหรับ Neural network ยังไม่ได้เข้าสู่การ Training model เนื่องจากการทำโมเดลมีรายละเอียดที่ต้อง Deep down ลงไป จึงขอจบตอนนี้ไว้เพียงเท่านี้ก่อน ตอนหน้าเป็นเรื่องเกี่ยวกับโมเดล Network ทั้งหมด
