Part 3: Survival analysis in Credit Risk Model
The Final chapter of survival analysis in credit risk model.
เนื้อสำหรับตอนสุดท้ายของการ Survival analysis สำหรับการหา Probability of Default model (PD Model) แพลนไว้ว่าตอนนี้คงเป็นตอนสุดท้ายแล้ว แต่ยังคิดเนื้อหาที่สามารถต่อยอดจาก Model นี้ได้อีกบ้าง ดังนั้นอาจมีตอนต่อ ๆ ไปที่ยังใช้พื้นฐานจาก Model นี้ได้อยู่ ก่อนเข้าเนื้อหาตอนนี้ แนะนำให้อ่านย้อนหลัง 2 ตอนก่อนหน้านี้ก่อนตาม Links ที่ให้ไว้ด้านล่าง
Summary table
เริ่มเปิดเนื้อหาตอนด้วย Summary table เพราะจากตอนก่อนหน้านี้ Dataset ได้ทำสร้าง Flag และ Exclusion สิ่งที่ไม่ต้องการออกทั้งหมดแล้ว ดังนั้นจึงเหลือเพียงแค่การทำสรุปผล Model เท่านั้น
แต่การทำ Summary table มีสิ่งที่ต้องพิจารณาคือเรื่อง Time period ที่ควรมีความ Consistency กัน เพราะทั้งหมดนี้อาจส่งผลต่อ Population sample ของแบบจำลอง หากยังจำกันได้ การหา Default event ของแต่ละ Transaction แต่การ Observe ในลักษณะของ Monthly basis คือการ Observe ไปข้างหน้าละที 1 เดือน
นอกจากนี้ยังมี Key aggregation ที่สร้างเอาไว้คือ “ปี” ที่ทำการ Observe โดยข้อมูลทั้งหมดมีตั้งแต่ปี 2014 ถึงปี 2019 เมื่อพิจารณาเรื่อ Exclusion criteria ประกอบแล้ว พบว่าสุดท้ายที่ปี 2019 ไม่สามารถใช้เป็น Observation year ได้ เพราะต้องทิ้งข้อมูลให้สำหรับการ Estimate 12-Month PD แต่ยังใช้ Default status ที่เกิดขึ้นสร้างเป็น Probability ได้ ดังนั้นข้อมูลที่ Observe ได้ทั้งหมดจึงเป็นเหมือนรูปด้านล่าง

โดยสรุปเรื่องของ Length ที่สามารถ Observe ได้ จากตารางประกอบด้านบน สามารถสรุปได้ว่า Observation year ที่สามารถมองได้ไกลที่สุดอยู่ที่ปี 2014 เพราะเป็นจุดตั้งต้นที่มีข้อมูลเยอะที่สุด จึงสามารถ Observe ได้ตั้งแต่ 2014 ไปจนถึง 2019 รวมระยะเวลาทั้งหมด 6 ปี หากขยับ Observation year มาที่ 2015 จะสามารถ Observe ได้ตั้งแต่ 2015 ถึง 2019 รวมระยะเวลาทั้งหมด 5 ปี ทั้งหมดนี้สามารถสรุปเป็นรูปประกอบได้เหมือนด้านล่าง

การสร้างเป็น Observation year อาจไม่ละเอียดเท่ากับการสร้าง Year แบบ Month ชน Month เช่น Mar-2014 ถึง Mar-2015 เป็นต้น แต่ทิ้งไว้เป็น Assumption ของโมเดลมา ณ ที่นี้
เมื่อเข้าใจ Concept การสร้าง Summary table ในภาพรูปแล้ว ก็สามารถ Construct เป็น Survival curves ได้ตามต้องการ แต่ยังมีอีกเรื่องที่ต้องคำนึงคือ ในบางเดือนอาจไม่สามารถ Observe default observation ได้ตามตัวอย่างด้านล่าง

เช่น Observation month ที่ 5 ไม่มี Transaction ที่ Default อยู่เลย ดังนั้นจึงเกิดเป็นอีก 1 Assumption สำหรับแบบจำลองนี้คือ การ Retain ค่า Cumulative default จาก Observed month ก่อนหน้า เพื่อทำให้เป็น Survival curve ในรูปแบบ Cumulative value

จากตัวอย่างจะเห็นได้ว่าใช้การ Retain จำนวน Cumulative default จาก Observation month ที่ 4 คือจำนวน 8 Transaction มาที่ Observation month ที่ 5 และสร้างเป็น Cumulative survival curve ได้จาก ผลรวม Cumulative default ในแต่ละเดือน หารด้วยผลรวมจากจำนวน Observation ที่ Observed year ทั้งหมดคือ 1,860 ผลลัพธ์ที่ออกจะได้เป็นตามรูปด้านล่าง

เมื่อเข้าใจ Model assumption ทั้งหมดแล้ว สามารถนำ Logic ทั้งหมดที่เล่านี้ไปทำเป็น Code เพื่อสร้างแบบจำลองออกเป็นขั้นตอนสุดท้าย
Code
เขียน Comment เอาไว้มากมาย แต่เป็นสิ่งที่ได้อธิบายไปทั้งหมดจาก Section ก่อนหน้านี้ สำหรับ Code chuck นี้เป็นการสร้าง Table เปล่าเอาไว้เพื่อรอผลสรุปจาก Transaction data ที่มีการ Flag lifetimeFlag และ times ไว้แล้วจากตอนก่อนหน้านี้
การสร้าง DataFrame เป็นไปตามข้อมูลที่มีคือ
- มีข้อมูลทั้งหมด 2 Segment
- ในแต่ละ Segment แบ่ง Risk grades ออกเป็นทั้งหมด 4 Grades (0–3)
- ในแต่ละ Risk grades แบ่ง Observation year ออกเป็นทั้งหมด 5 Years (2014–2018)
- ในแต่ละ Observation year แบ่ง Observation time ออกเป็น 60 Months ของปี 2014, 48 Months ของปี 2015, 36 Months ของปี 2016, 24 Months ของปี 2017 และ 12 Months ของปี 2018
ใน Iteration ซ้อนใน Iteration ตาม Logic ที่อธิบายไว้ เมื่อถึง Iteration ชั้นสุดท้าย ให้ใช้ zip() เพื่อรับทั้งหมด 2 ตัวแปรให้ทำงานพร้อมกัน คือ year และ time โดยที่ time สามารถสร้างเป็น range() ติดลบ เพื่อให้ถอย Value ลงไปเรื่อย ๆ ในขณะที่ year เพิ่มขึ้นทีละ 1
ภายใน Iteration ให้สร้างเป็น DataFrame ที่มี Column times โดยเป็นค่าของ range() ของ time ตั้งแต่ 1 ไปจนถึง time สุดท้ายที่หาได้จาก Iteration ส่วน Values ใน Columns อื่น เช่น Year, Aging และ Segment เป็นค่าคงที่ สามารถเติมเข้ามาทีหลังได้ จากนั้นใช้ pd.concat() เพื่อต่อ DataFrame เข้าด้วยกันแบบ axis = 0 เพื่อให้ต่อแบบ Row
สร้างเป็นตัวแปร DataFrame ใหม่ทั้งหมด 2 ตัวเพื่อนับ Observation ทั้งหมดในแต่ละ Observation year และนับจำนวน Default ทั้งหมดในแต่ละ Observation time
Merge DataFrame ที่สร้างไว้เข้ากับ DataFrame เปล่าที่สร้างจากเงื่อนไข Summary โดยเริ่มจาก Merge จำนวน Observation แต่ในละปีก่อน เนื่องจากมีจำนวนเท่ากัน จากนั้นให้ Merge จำนวน Default แต่ละ Observed time
เติม DataFrame ด้วย Assumption สุดท้ายที่ต้อง Retail cumulative bad หากมีค่า Missing value เกิดขึ้น โดยค่า Default ของ .cumsum() เป็นการ Ignore missing value อยู่แล้ว ดังนั้นสามารถใช้ .cumsum() ก่อนแล้วใช้ .ffill() เพื่อเติมช่องว่างด้วยการ Retain value จาก Row ก่อนหน้าได้
ขั้นตอนสุดท้ายเป็นการ Cumulative default rate ของแต่ละปี ใช้ cumBad / N ได้เลยตรง ๆ แต่ครั้งนี้ลองใช้ .eval() ในการสร้าง Column ใหม่ เพราะมีความ Efficient มากกว่า
Result
Section นี้ไม่มีอะไรนอกจากเป็นการ Plot results ที่เกิดขึ้นทั้งหมดจาก Survival analysis model
Segment: CU
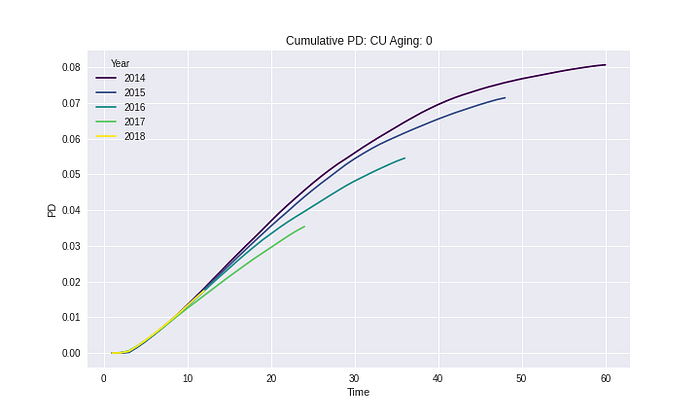

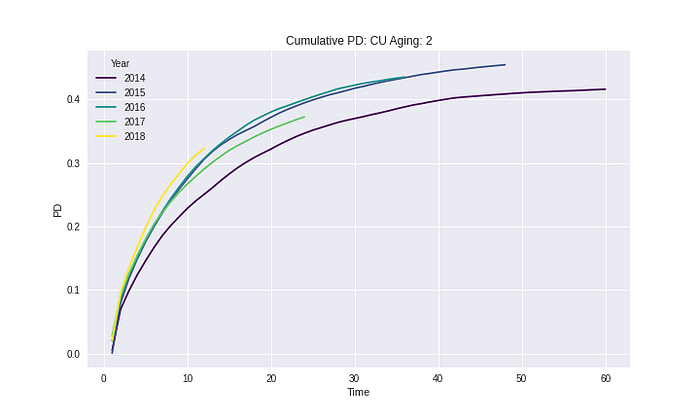
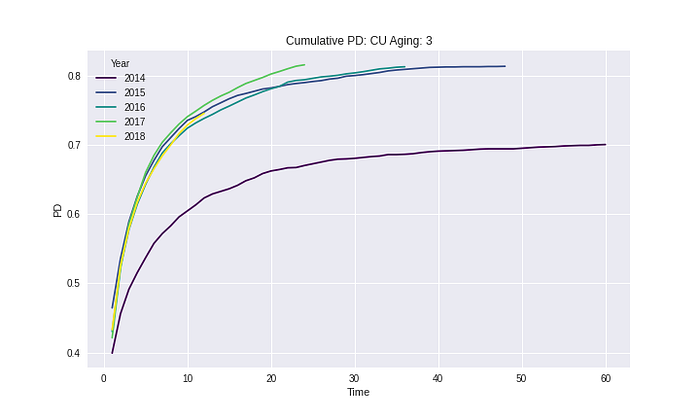
Segment: HU
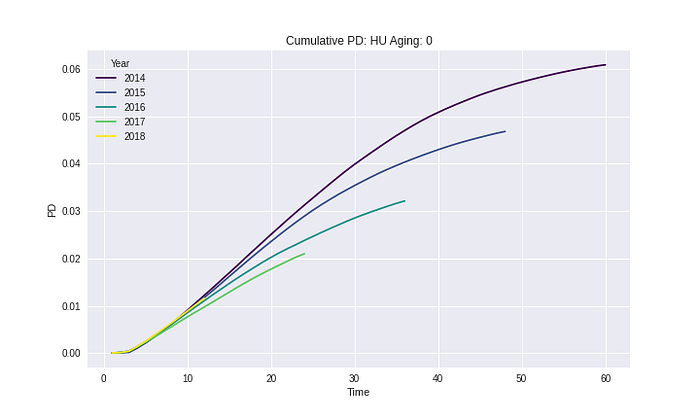
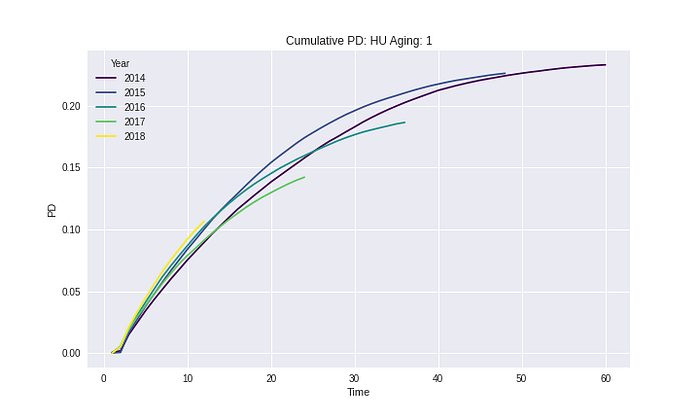
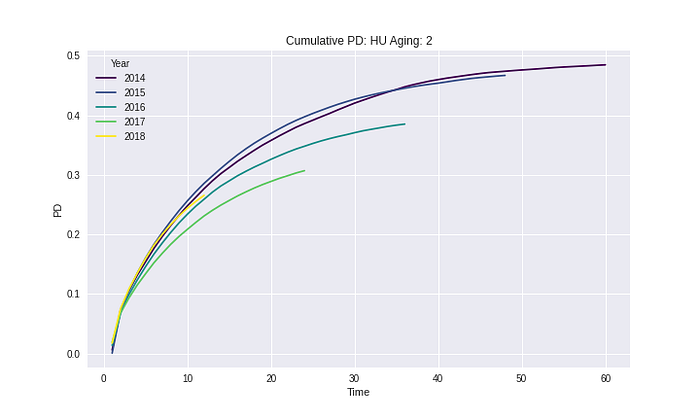
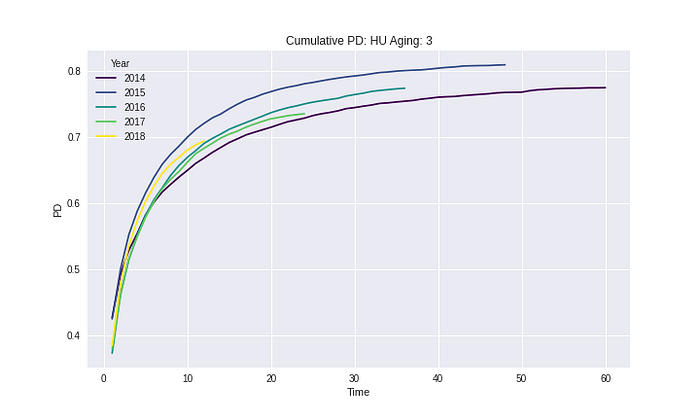
จาก Results ในทุก Segment และ Risk grades เห็นได้ว่า Cumulative PD ไม่มีค่าที่ลดลงในทุก ๆ ช่วงเวลา ซึ่งวิธีการนี้ยังทำให้ความหมายของ Cumulative PD ไม่ได้ผิดไป
ทำ Summary table ในรูปแบบ Wide format เพื่อใช้ในงานต่อไป
Conclusion
ก่อนจบโมเดลนี้ ขอ Export ข้อมูลที่ได้จากแบบจำลองเก็บไว้ เพื่อใช้งานต่อไป และหา Default rate ที่เกิดขึ้นในแต่ละ Risk grade และในแต่ละเดือน (และทั้งสองอย่าง) เก็บไว้สำหรับเนื้อหา IFRS 9 เผื่อได้เขียนถึงอีก
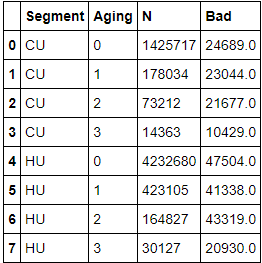
ในตอนนี้แบบจำลองสามารถใช้งานได้แล้ว แต่ยังมีจุดที่สามารถ Improve ให้มีความสมเหตุสมผลมากยิ่งขึ้น ซึ่ง Weakness และการ Improve คงมีโอกาสได้เขียนถึงในตอนต่อ ๆ ไป
สำหรับ Colab Notebook สามารถดูได้ที่ GitHub ที่ให้ไว้ด้านบน
