หา Imputed factor ด้วย Chain Ladder สำหรับการต่อเส้นกราฟ
We forge the chains we wear in life.
ยังอยู่ในเนื้อหาที่เกี่ยวกับการ Development Credit Risk Model ด้วย Survival analysis แต่เนื้อหาในตอนนี้ อาจไม่ได้เกี่ยวข้องโดยตรงกับ PD Model จากตอนก่อนหน้านี้ เพราะเนื้อหาในตอนนี้ อาจนำไปใช้กับโจทย์โมเดลแบบอื่น ๆ ได้ ซึ่งเป็นเรื่องของการ Imputation หรือการเติม Missing ด้วยวิธีการต่าง ๆ ในตอนนี้ขอเสนอวิธีการเติมค่าด้วย Chain Ladder
มี Python library ที่ทำงานเกี่ยวกับ Chain Ladder โดยตรง เพราะนอกจากการใช้ในการ Imputation แล้ว Chain Ladder ยังสามารถใ้ช้ทำอะไรอย่างอื่นได้อีกมาก แต่ในตอนนี้ไม่ได้ใช้ Library ดังกล่าว สามารถอ่านเพิ่มเติมได้จาก Link นี้
Why Chain Ladder?
ทำไม Chain Ladder ถึงมีความสำคัญต่อ Survival analysis โดยเฉพาะ PD Model จากข้อมูลที่เกิดขึ้นจากโมเดลของตอนก่อนหน้านี้
ข้อมูลที่ใช้ใน Blog ตอนนี้เป็นผลผลิตจาก Survival analysis model ที่สร้างเป็น PD Curves by observation year ทิ้งไว้จากตอนก่อนหน้านี้ สามารถ Refer กลับไป Colab Notebook หรือย้อนกลับไปอ่านที่ Blog ได้จาก Link ด้านล่างทั้ง 2 Links เพื่อให้เข้าใจที่มาทั้งหมด
หรือหากอยากเริ่มต้นจาก Dataset สุดท้ายที่เป็น Input สำหรับตอนนี้ ก็สามารถ Import ได้จาก GitHub link นี้
เขียนเป็น Function สำหรับการหาค่าเฉลี่ยแบบ Weighted average จำนวน Observation และ Function สำหรับการ Plot เอาไว้ เนื่องจากต้องมีการทำงานลักษณะนี้หลายรอบ
ผลลัพธ์ที่ออกมาของทั้ง 2 Segments คือ
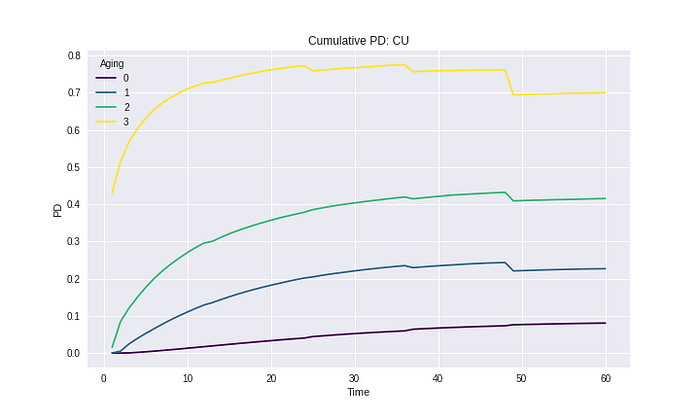
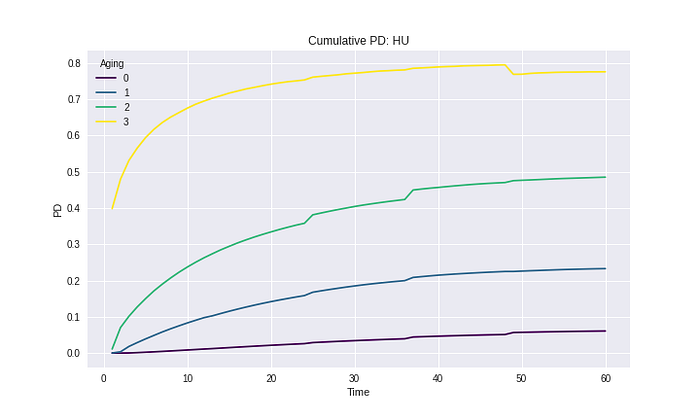
เมื่อลองคำนวณหาค่าเฉลี่ยของแต่ละ Risk grade ที่คำนวณจากระดับ Observation year จะพบว่ามีบาง Period ที่ค่า Cumulative PD มีค่า Drop ลงจาก Period ก่อนหน้านี้ ซึ่งผิดความหมายของ Cumulative ทั้ง ๆ ที่โมเดลคำนวณมาจากค่าที่เป็น Cumulative แล้ว
เหตุผลที่เกิดเหตุการณ์นี้ขึ้น เพราะว่าที่ช่วง Observation year ท้าย ๆ ค่าเฉลี่ยที่เกิดขึ้น เกิดจากข้อมูลของปีแรก ๆ ที่ Observe เท่านั้น เพราะข้อมูลช่วงปีแรก ๆ เท่านั้นที่มีความยาวมากพอที่จะ Cover period ทั้งหมดได้ ดังนั้นหากข้อมูลปีแรกมีค่า PD ที่ต่ำ เมื่อเฉลี่ยรวมกันแล้ว ทำให้ Cumulative PD มีโอกาส Drop ได้
Chain Ladder
Chain Ladder เป็นเทคนิคที่ใช้ในการ Estimate ข้อมูลนอกเหนือจากช่วงเวลาที่มีข้อมูลจริงอยู่ โดยใช้ข้อมูลที่ Available อาจมากหรือน้อยขึ้นอยู่กับ Assumption ของโมเดลที่ใช้ เทคนิคนี้ส่วนมากพบเจอในโมเดลที่ต้องการ “ต่อเส้น” เช่น Survival analysis หรือ Loss triangle model
พูดถึงการต่อเส้น มีคำศัพท์เทคนิคเรียกว่า Claim Reserving Estimation หรือ Tail Estimation เป็นการหา Slope (Factor) หรือเรียกว่า Development factor ของข้อมูลที่ยัง Available อยู่นำไป Apply (ไม่ว่าทางใดทางหนึ่ง) เพื่อสร้างข้อมูลใหม่

ตัวอย่างจากข้อมูลตอนก่อนหน้านี้ ตัดข้อมูลจาก Observation ของปีสุดท้ายใน 12 เดือนแรก เพื่อให้ดูวิธีการคำนวณ Development factor จากรูปจะเห็นได้ว่าตารางที่เป็นสีเทามีค่า Missing เนื่องจาก Assumption ของโมเดลที่ไม่สามารถ Observed ได้ ดังนั้นเพื่อป้องกันปัญหาที่อาจเกิดขึ้นจาก Section ก่อนหน้านี้ ที่แสดงค่าเฉลี่ยให้ดูแล้ว ข้อมูลที่เป็นสีเทาจึงต้องมีการ Imputation

การหา Development factor สำหรับ Chain Ladder สามารถคำนวณได้จาก Slope ของข้อมูลตามช่วงเวลา เช่น ต้องการ Factor ที่จุด Observed ที่ 13 ของปี 2018 จึงคำนวณได้จากผลรวมของข้อมูลที่ Available ทั้งหมดตั้งแต่ปี 2014–2017 ของจุด Observed ที่ 13 หารด้วยผลรวมทั้งหมดของข้อมูลที่ Available ทั้งหมดตั้งแต่ ทั้งหมดตั้งแต่ปี 2014–2017 ของจุด Observed ที่ 12 การ Weighted ด้วยค่าน้ำหนักใด ๆ อาจขึ้นอยู่กับ Assumption ของแต่ละโมเดล แต่ในที่นี้มีการ Weighted ด้วยจำนวน Observation ทั้งหมด
จากวิธีการที่อธิบายไว้ด้านบน Development factor ตัวแรก จึงสามารถคำนวณได้ 21309.99 / 18988 = 1.12 เป็นต้น
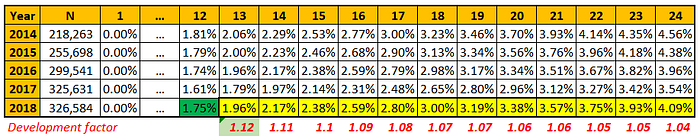
เมื่อได้ Development factor ทั้งหมดแล้ว สามารถใช้ Factor ในการ Imputation ข้อมูลได้ จากตัวอย่างที่ต้องการ Impute ข้อมูลของเดือนที่ 13 สามารถทำได้โดยใช้ข้อมูลล่าสุดที่ Available ที่เดือนที่ 12 คูณกับ Development factor คือ 1.75% * 1.12 = 1.96% เมื่อได้ 1.96% ก็สามารถหาค่าของเดือนต่อ ๆ ไปได้ด้วย Logic เดียวกัน เช่น ค่าที่เดือน 14 จึงเท่ากับ 1.96 * 1.11 = 2.17% เป็นต้น
Code
Section เป็นการนำเอา Logic ที่ได้อธิบายไปใน Section ก่อนหน้ามาทำเป็น Code ซึ่งหากเข้าใจ Logic ทั้งหมดแล้ว Code ก็เป็นค่าทำ Iteration ซ่อนกันเท่านั้น
DataFrame ที่เป็น Input คือข้อมูลที่เป็นลักษณะ Wide format โดยการทำ Chain Ladder เป็นการทำบน Risk grade level ดังนั้น 2 Iteration แรกจึงเป็นการเลือก Row จาก DataFrame และตัดข้อมูลที่ต้องการใช้งานออกมา
Columns แรกที่ได้ออกมาคือ N หรือจำนวณ Observation ในแต่ละปี ดังนั้นใน Iteration ที่ 3 จึงเลือกทำงานตั้งแต่ Columns ที่ 1 เป็นต้นไป (ข้าม N)
จากนั้นต้องเลือก Columns ทั้งหมด 2 Columns เพื่อใช้ในการคำนวณ โดยต้องเริ่มจาก Columns ที่มีค่า Missing values เป็น Column ที่ 2 หาเจอ เก็บไว้ในตัวแปร forward ใช้ If statement เพื่อ Check condition ว่ามีค่า Missing value หรือไม่ด้วย .isnull().any() เมื่อ If statement ตอบ True ก็สามารถหา current ที่เป็นตัวส่วนของ Development factor ได้เช่นกัน
ใช้ np.nansum() เพื่อให้รวมผลลัพธ์ใน Array โดยที่ไม่สนใจ np.nan จากนั้น Weighted ด้วยค่า Observation ที่เป็น Column แรกของ DataFrame เสมอ จึง Fix position ที่ .iloc[:, 0] ได้เลย .append() ผลลัพธ์แต่ละรอบเพื่อเก็บ Development factor
สำหรับ break และ pass statement มีไว้เพื่อป้องกัน Iteration error จาก i ที่เกิน Maximum bounds
ทำ Development factor ทั้งหมดที่หาได้เป็น Numpy array เพื่อ .reshape() เป็นมิติที่เราสามารถใช้งานได้ง่าย ๆ โดยให้ .reshape() มีขนาดเป็น 2 มิติ เก็บค่าตาม Risk grade level ที่คิด Development factor ขึ้นมา
ขั้นตอนสุดท้ายคือการนำ Development factor ไปคูณให้ถูก Position ทั้ง Segment และ Risk grade ใช้ Iteration กับ enumerate() เพื่อรับค่า Index จากนั้นเลือก DataFrame สำหรับใช้ในการคูณ และเลือก factors จาก Numpy array ที่เก็บค่าไว้ โดยใช้ Index ของ Iteration ชั้นแรกคูณด้วยจำนวณ Unique ของ Risk grade และบวกด้วย Index ของ Iteration ชั้นที่สอง ผลลัพธ์ที่ออกมาคือ Range ของตัวเลขที่เรียงลำดับตาม Segment และ Risk grade ของ Iteration ที่ใช้คำนวณและเก็บ Development factor
จากนั้นให้นำ DataFrame มาคูณกับ Numpy array ตามค่า Missing value ที่เกิดขึ้นในแต่ละ Cell ใช้ Iteration 2 ชั้น ทั้ง Columns และ Rows และ If statement เพื่อ Check missing ด้วย pd.isnull() โดยหาก If statement ตอบ True ก็ให้เลือก Cell ก่อนหน้าที่จะเกิดขึ้น Missing ด้วย .iloc[j, i-1] (-1 คือเอา Column ก่อนหน้านี้) คูณด้วย Array ของ factor ที่ลบด้วย 12 เพราะ Development factor เริ่มหาจากจุดที่เริ่มมีค่า Missing value ดังนั้น Observed 12 เดือนแรกยังไม่จำเป็นต้องหา Development factor หรือในอีกความหมายคือ Development factor เริ่มต้นที่เดือนที่ 13 แต่เมื่อ Iteration มี i เกินไป 12 Index แล้วจึงต้องลบออก
เมื่อรันเสร็จแล้วค่า Missing values ก่อนหน้านี้จะถูกเติมด้วย Chain Ladder ทั้งหมด ทำให้ Curves ของแต่ละ Observation year ที่สั้นบ้างยาวบ้าง มีความยาวเท่ากันทั้งหมด
สามารถเรียกใช้ Function ที่เขียนไว้สำหรับการ Plot ผลลัพธ์ที่ได้คือรูปด้านล่าง
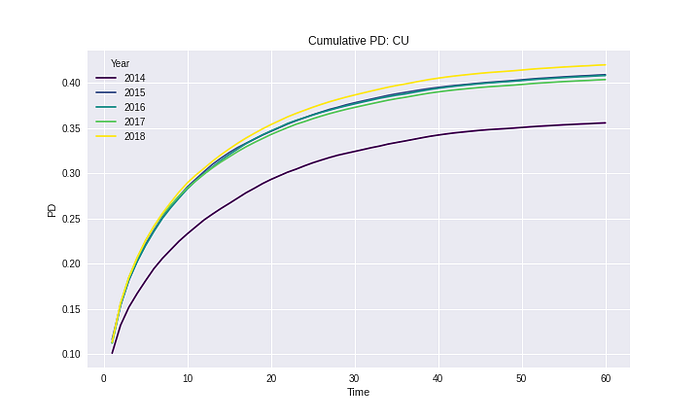
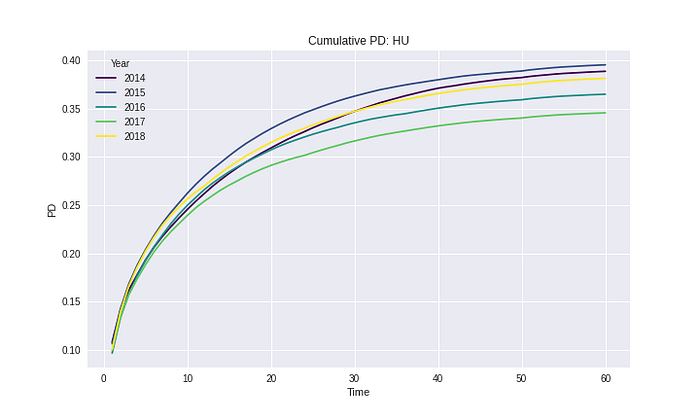
เส้น Cumulative จากเดิมที่มีความสั้นยาวตามแต่ละปีที่สามารถ Observe ได้ จะเปลี่ยนไปเป็นเส้นที่มีความยาวเท่ากัน
ดังนั้นเมื่อหาค่าเฉลี่ยจากเส้นทั้งหมดนี้ ผลลัพธ์ที่ออกมาคือ Cumulative PD ไม่มีค่าที่ Drop ลงแล้ว
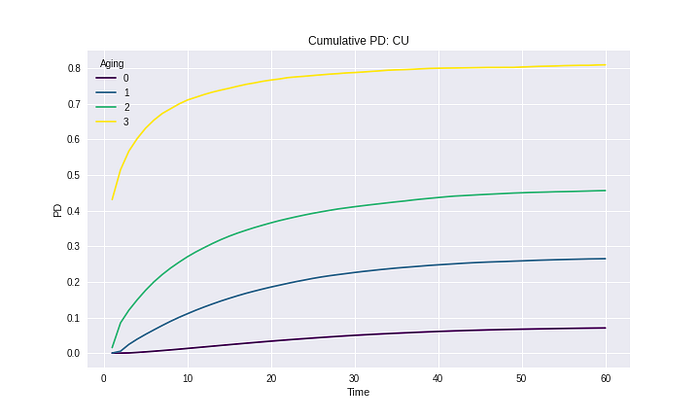
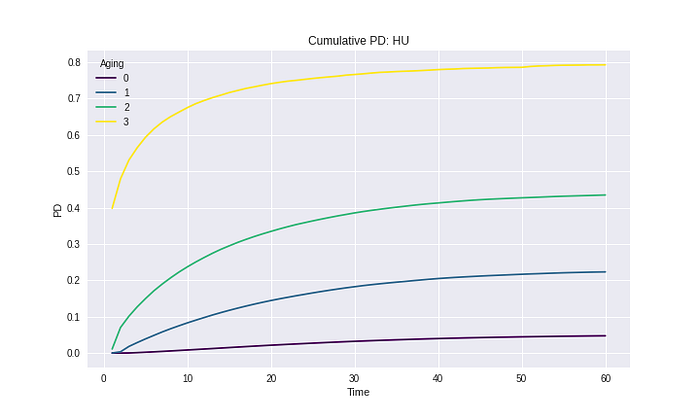
Conclusion
ในความเป็นจริงแล้ว Chain Ladder เป็นวิธีการใหญ่ ๆ ที่สามารถแตกแขนงแยกย่อยออกได้เป็นอีกหลายวิธี ซึ่งวิธีการที่นำเสนอในตอนนี้ เป็นวิธีการที่นิยมใช้ใน Survival model เมื่อต่าง Model ออกไป จึงมีเวลาการนำไปใช้งานที่หลากหลายกว่าเดิม
Colab Notebook ของ Chain Ladder สามารถดูได้ที่ GitHub ที่ให้ไว้ด้านบน
